Lecture 1 | Machine Learning (Stanford)Lecture by Professor Andrew Ng for Machine Learning (CS 229) in the Stanford Computer Science department. Professor Ng provides an overview of the course in this introductory meeting.
This course provides a broad introduction to machine learning and statistical pattern recognition. Topics include supervised learning, unsupervised learning, learning theory, reinforcement learning and adaptive control. Recent applications of machine learning, such as to robotic control, data mining, autonomous navigation, bioinformatics, speech recognition, and text and web data processing are also discussed.
Complete Playlist for the Course:
http://www.youtube.com/view_play_list?p=A89DCFA6ADACE599
Stanford University Channel on YouTube:
http://www.youtube.com/stanford
Lecture 01 - The Learning ProblemThe Learning Problem - Introduction; supervised, unsupervised, and reinforcement learning. Components of the learning problem. Lecture 1 of 18 of Caltech's Machine Learning Course - CS 156 by Professor Yaser Abu-Mostafa. View course materials in iTunes U Course App - https://itunesu.itunes.apple.com/audit/CODBABB3ZC and on the course website - http://work.caltech.edu/telecourse.html
Produced in association with Caltech Academic Media Technologies under the Attribution-NonCommercial-NoDerivs Creative Commons License (CC BY-NC-ND). To learn more about this license, http://creativecommons.org/licenses/by-nc-nd/3.0/
This lecture was recorded on April 3, 2012, in Hameetman Auditorium at Caltech, Pasadena, CA, USA.
Using Python to Code by VoiceTavis RuddTwo years ago I developed a case of Emacs Pinkie (RSI) so severe my hands went numb and I could no longer type or work. Desperate, I tried voice recognition. At first programming with it was painfully slow but, as I couldn't type, I persevered. After several months of vocab tweaking and duct-tape coding in Python and Emacs Lisp, I had a system that enabled me to code faster and more efficiently by voice than I ever had by hand.
In a fast-paced live demo, I will create a small system using Python, plus a few other languages for good measure, and deploy it without touching the keyboard. The demo gods will make a scheduled appearance. I hope to convince you that voice recognition is no longer a crutch for the disabled or limited to plain prose. It's now a highly effective tool that could benefit all programmers.
Python-Powered Machine Learning in the CloudStephen Hoover
http://www.pyvideo.org/video/3556/python-powered-machine-learning-in-the-cloud
Python is a powerful, easy-to-use language which now has a wide range of numerical and machine-learning open source libraries. At Civis Analytics, we've built a cloud-based platform for data science which empowers analysts to extract insights from their data with less effort. The platform itself runs on Amazon Web Services, and the machine learning workflows at the core of the platform are coded in Python. Open-source Python libraries such as pandas, numpy, statsmodels, and scikit-learn let our data scientists focus on high-level workflows and greatly accelerate our development process. In this talk, I'll give an overview of Civis's new data science platform, focusing on the machine-learning aspects. I'll talk about how we use Python open-source libraries to help with data analysis, and some of the challenges we've overcome along the way.
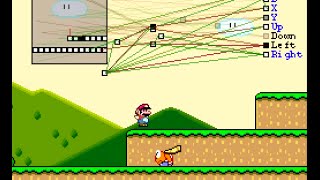
MarI/O - Machine Learning for Video GamesMarI/O is a program made of neural networks and genetic algorithms that kicks butt at Super Mario World.
Source Code: http://pastebin.com/ZZmSNaHX
"NEAT" Paper: http://nn.cs.utexas.edu/downloads/papers/stanley.ec02.pdf
Some relevant Wikipedia links:
https://en.wikipedia.org/wiki/Neuroevolution
https://en.wikipedia.org/wiki/Evolutionary_algorithm
https://en.wikipedia.org/wiki/Artificial_neural_network
BizHawk Emulator: http://tasvideos.org/BizHawk.html
Neural Network Training (Part 1): The Training ProcessFrom http://www.heatonresearch.com. In this series we see how neural networks are trained. This part overviews the training process.
Lec-1 Introduction to Artificial Neural NetworksLecture Series on Neural Networks and Applications by Prof.S. Sengupta, Department of Electronics and Electrical Communication Engineering, IIT Kharagpur. For more details on NPTEL visit http://nptel.iitm.ac.in
Visualizing and Understanding Deep Neural Networks by Matt ZeilerFor more tech talks and to network with other engineers, check out our site https://www.hakkalabs.co/logs
Matthew Zeiler, PhD, Founder and CEO of Clarifai Inc, speaks about large convolutional neural networks. These networks have recently demonstrated impressive object recognition performance making real world applications possible. However, there was no clear understanding of why they perform so well, or how they might be improved. In this talk, Matt covers a novel visualization technique that gives insight into the function of intermediate feature layers and the operation of the overall classifier. Used in a diagnostic role, these visualizations allow us to find model architectures that perform exceedingly well.
The Next Generation of Neural NetworksGoogle Tech Talks
November, 29 2007
In the 1980's, new learning algorithms for neural networks promised to solve difficult classification tasks, like speech or object recognition, by learning many layers of non-linear features. The results were disappointing for two reasons: There was never enough labeled data to learn millions of complicated features and the learning was much too slow in deep neural networks with many layers of features. These problems can now be overcome by learning one layer of features at a time and by changing the goal of learning. Instead of trying to predict the labels, the learning algorithm tries to create a generative model that produces data which looks just like the unlabeled training data. These new neural networks outperform other machine learning methods when labeled data is scarce but unlabeled data is plentiful. An application to very fast document retrieval will be described.
Speaker: Geoffrey Hinton
Geoffrey Hinton received his BA in experimental psychology from Cambridge in 1970 and his PhD in Artificial Intelligence from Edinburgh in 1978. He did postdoctoral work at Sussex University and the University of California San Diego and spent five years as a faculty member in the Computer Science department at Carnegie-Mellon University. He then became a fellow of the Canadian Institute for Advanced Research and moved to the Department of Computer Science at the University of Toronto. He spent three years from 1998 until 2001 setting up the Gatsby Computational Neuroscience Unit at University College London and then returned to the University of Toronto where he is a University Professor. He holds a Canada Research Chair in Machine Learning. He is the director of the program on "Neural Computation and Adaptive Perception" which is funded by the Canadian Institute for Advanced Research.
Geoffrey Hinton is a fellow of the Royal Society, the Royal Society of Canada, and the Association for the Advancement of Artificial Intelligence. He is an honorary foreign member of the American Academy of Arts and Sciences, and a former president of the Cognitive Science Society. He received an honorary doctorate from the University of Edinburgh in 2001. He was awarded the first David E. Rumelhart prize (2001), the IJCAI award for research excellence (2005), the IEEE Neural Network Pioneer award (1998) and the ITAC/NSERC award for contributions to information technology (1992).
A simple introduction to Geoffrey Hinton's research can be found in his articles in Scientific American in September 1992 and October 1993. He investigates ways of using neural networks for learning, memory, perception and symbol processing and has over 200 publications in these areas. He was one of the researchers who introduced the back-propagation algorithm that has been widely used for practical applications. His other contributions to neural network research include Boltzmann machines, distributed representations, time-delay neural nets, mixtures of experts, Helmholtz machines and products of experts. His current main interest is in unsupervised learning procedures for neural networks with rich sensory input.
Neural Bots - Evolving Artificial IntelligenceEvolving AI using Neural Networks
Speech Recognition Breakthrough for the Spoken, Translated WordChief Research Officer Rick Rashid demonstrates a speech recognition breakthrough via machine translation that converts his spoken English words into computer-generated Chinese language. The breakthrough is patterned after deep neural networks and significantly reduces errors in spoken as well as written translation.
For more information on Speech Recognition and Translation, visit http://www.microsoft.com/translator/skype.aspx
Learning from Bacteria about Social NetworksGoogle Tech Talk (more info below)
September 30, 2011
Presented by Eshel Ben-Jacob.
ABSTRACT
Scientific American placed Professor Eshel Ben-Jacob and Dr. Itay Baruchi's creation of a type of organic memory chip on its list of the year's 50 most significant scientific discoveries in 2007. For the last decade, he has pioneered the field of Systems Neuroscience, focusing first on investigations of living neural networks outside the brain.
http://en.wikipedia.org/wiki/Eshel_Ben-Jacob
Learning from Bacteria about Information Processing
Bacteria, the first and most fundamental of all organisms, lead rich social life in complex hierarchical communities. Collectively, they gather information from the environment, learn from past experience, and make decisions. Bacteria do not store genetically all the information required to respond efficiently to all possible environmental conditions. Instead, to solve new encountered problems (challenges) posed by the environment, they first assess the problem via collective sensing, then recall stored information of past experience and finally execute distributed information processing of the 109-12 bacteria in the colony, thus turning the colony into super-brain. Super-brain, because the billions of bacteria in the colony use sophisticated communication strategies to link the intracellular computation networks of each bacterium (including signaling path ways of billions of molecules) into a network of networks. I will show illuminating movies of swarming intelligence of live bacteria in which they solve optimization problems for collective decision making that are beyond what we, human beings, can solve with our most powerful computers. I will discuss the special nature of bacteria computational principles in comparison to our Turing Algorithm computational principles, showing that we can learn from the bacteria about our brain, in particular about the crucial role of the neglected other side of the brain, distributed information processing of the astrocytes.
Eshel Ben-Jacob is Professor of Physics of Complex Systems and holds the Maguy-Glass Chair in Physics at Tel Aviv University. He was an early leader in the study of bacterial colonies as the key to understanding larger biological systems. He maintains that the essence of cognition is rooted in the ability of bacteria to gather, measure, and process information, and to adapt in response. For the last decade, he has pioneered the field of Systems Neuroscience, focusing first on investigations of living neural networks outside the brain and later on analysis of actual brain activity. In 2007, Scientific American selected Ben-Jacob's invention, the first hybrid NeuroMemory Chip, as one of the 50 most important achievements in all fields of science and technology for that year. The NeuroMemory Chip entails imprinting multiple memories, based upon development of a novel, system-level analysis of neural network activity (inspired by concepts from statistical physics and quantum mechanics), ideas about distributed information processing (inspired by his research on collective behaviors of bacteria) and new experimental methods based on nanotechnology (carbon nanotubes). Prof. Ben-Jacob received his PhD in physics (1982) at Tel Aviv University, Israel. He served as Vice President of the Israel Physical Society (1999-2002), then as President of the Israel Physical Society (2002-2005), initiating the online magazine PhysicaPlus, the only Hebrew-English bilingual science magazine. The general principles he has uncovered have been examined in a wide range of disciplines, including their application to amoeboid navigation, bacterial colony competition, cell motility, epilepsy, gene networks, genome sequence of pattern-forming bacteria, network theory analysis of the immune system, neural networks, search, and stock market volatility and collapse. He has examined implications of bacterial collective intelligence for neurocomputing. His scientific findings have prompted studies of their implications for computing: using chemical "tweets" to communicate, millions of bacteria self-organize to form colonies that collaborate to feed and defend themselves, as in a sophisticated social network.
This talk was hosted by Boris Debic, and arranged by Zann Gill and the Microbes Mind Forum.
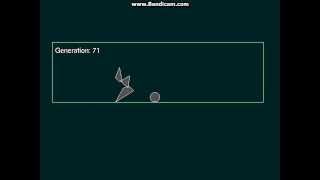
Genetic algorithm. Learning to jump over ball.Automated design of motion strategy using genetic algorithm and neural network. Learning simple creature to jump over ball.
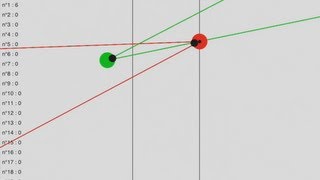
A genetic algorithm learns how to fight!For more details about the neural network, the programming, click here : http://doublezoom.free.fr/programmation/AG_Exemple_Fighting.php (french)
This is an implementation of a genetic algorithm on a neural network. The "fighters" are capable of self-improvement in order to become stronger.
As you can see, the "fighters" are learning how to fight. Each one of them can see the bullets and the enemy in their vision field (represented by two lines), and have 5 possible actions : move forward, turn right, turn left, shoot and adjust their field of view.
This program was done in lua, on my iPad, thanks to codea (http://twolivesleft.com/Codea/)
The music, Five Armies by Kevin MacLeod is licensed under a CC Attribution 3.0.
Introduction to Deep Learning with Pythonhttp://indico.io
Alec Radford, Head of Research at indico Data Solutions, speaking on deep learning with Python and the Theano library. The emphasis of the talk is on high performance computing, natural language processing using recurrent neural nets, and large scale learning with GPUs.
SlideShare presentation is available here: http://slidesha.re/1zs9M11
____
indico is building the steel mill for the next industrial revolution. We are making productivity tools for data scientists at small and medium businesses by uniquely automating parts of their workflow.
Like Adobe bringing the creative suite to desktop publishing, making every designer a web developer. indico is bringing tools and workflow to machine learning, making every programmer a 10x data scientist.
Learn more at http://indico.io
Intro to Deep Learning with Theano and OpenDeep by Markus BeissingerDeep learning currently provides state-of-the-art performance in computer vision, natural language processing, and many other machine learning tasks. In this talk, we will learn when deep learning is useful (and when it isn't!), how to implement some simple neural networks in Python using Theano, and how to build more powerful systems using the OpenDeep package.
Our first model will be the 'hello world' of deep learning - the multilayer perceptron. This model generalizes logistic regression as your typical feed-forward neural net for classification.
Our second model will be an introduction to unsupervised learning with neural nets - the denoising auto-encoder. This model attempts to reconstruct corrupted inputs, learning a useful representation of your input data distribution that can deal with missing values.
Finally, we will explore the modularity of neural nets by implementing an image-captioning system using the the OpenDeep package.
Markus Beissinger
Recent graduate from the Jerome Fisher Program in Management and Technology dual degree program at the University of Pennsylvania (The Wharton School and the School of Engineering and Applied Science), and current Master's student in computer science. Focus on machine learning, startups, and management.
Slides: http://goo.gl/P9QGnV
Deep Learning: Intelligence from Big DataDeep Learning: Intelligence from Big Data
Tue Sep 16, 2014 6:00 pm - 8:30 pm
Stanford Graduate School of Business
Knight Management Center – Cemex Auditorium
641 Knight Way, Stanford, CA
A machine learning approach inspired by the human brain, Deep Learning is taking many industries by storm. Empowered by the latest generation of commodity computing, Deep Learning begins to derive significant value from Big Data. It has already radically improved the computer’s ability to recognize speech and identify objects in images, two fundamental hallmarks of human intelligence.
Industry giants such as Google, Facebook, and Baidu have acquired most of the dominant players in this space to improve their product offerings. At the same time, startup entrepreneurs are creating a new paradigm, Intelligence as a Service, by providing APIs that democratize access to Deep Learning algorithms. Join us on September 16, 2014 to learn more about this exciting new technology and be introduced to some of the new application domains, the business models, and the key players in this emerging field.
Moderator
Steve Jurvetson, Partner, DFJ Ventures
Panelists
Adam Berenzweig, Co-founder and CTO, Clarifai
Naveen Rao, Co-founder and CEO, Nervana Systems
Elliot Turner, Founder and CEO, AlchemyAPI
Ilya Sutskever, Research Scientist, Google Brain
** Follow (@VLAB) on Twitter and Event Hashtag #VLABdl
Deep Learning Lecture 10: Convolutional Neural NetworksSlides available at: https://www.cs.ox.ac.uk/people/nando.defreitas/machinelearning/
Course taught in 2015 at the University of Oxford by Nando de Freitas with great help from Brendan Shillingford.
Bay Area Vision Meeting: Unsupervised Feature Learning and Deep LearningBay Area Vision Meeting (more info below)
Unsupervised Feature Learning and Deep Learning
Presented by Andrew Ng
March 7, 2011
ABSTRACT
Despite machine learning's numerous successes, applying machine learning to a new problem usually means spending a long time hand-designing the input representation for that specific problem. This is true for applications in vision, audio, text/NLP, and other problems. To address this, researchers have recently developed "unsupervised feature learning" and "deep learning" algorithms that can automatically learn feature representations from unlabeled data, thus bypassing much of this time-consuming engineering. Building on such ideas as sparse coding and deep belief networks, these algorithms can exploit large amounts of unlabeled data (which is cheap and easy to obtain) to learn a good feature representation. These methods have also surpassed the previous state-of-the-art on a number of problems in vision, audio, and text. In this talk, I describe some of the key ideas behind unsupervised feature learning and deep learning, describe a few algorithms, and present case studies pertaining.
The Bay Area Vision Meeting (BAVM) is an informal gathering (without a printed proceedings) of academic and industry researchers with interest in computer vision and related areas. The goal is to build community among vision researchers in the San Francisco Bay Area, however, visitors and travelers from afar are also encouraged to attend and present. New research, previews of work to be shown at upcoming vision conferences, reviews of not-well-publicized work, and descriptions of "work in progress" are all welcome.
Recent Developments in Deep LearningGoogle Tech Talk
March 19, 2010
ABSTRACT
Presented by Geoff Hinton, University of Toronto.
Deep networks can be learned efficiently from unlabeled data. The layers of representation are learned one at a time using a simple learning module that has only one layer of latent variables. The values of the latent variables of one module form the data for training the next module. Although deep networks have been quite successful for tasks such as object recognition, information retrieval, and modeling motion capture data, the simple learning modules do not have multiplicative interactions which are very useful for some types of data.
The talk will show how to introduce multiplicative interactions into the basic learning module in a way that preserves the simple rules for learning and perceptual inference. The new module has a structure that is very similar to the simple cell/complex cell hierarchy that is found in visual cortex. The multiplicative interactions are useful for modeling images, image transformations, and different styles of human walking.
Learning Representations: A Challenge for Learning TheoryVideoLectures.Net Computer Science
View the talk in context: http://videolectures.net/colt2013_lecun_theory/
View the complete 26th Annual Conference on Learning Theory (COLT), Princeton 2013: http://videolectures.net/colt2013_princeton/
Speaker: Yann LeCun, Computer Science Department, New York University
License: Creative Commons CC BY-NC-ND 3.0
More information at http://videolectures.net/site/about/
More talks at http://videolectures.net/
Perceptual tasks such as vision and audition require the construction of good features, or good internal representations of the input. Deep Learning designates a set of supervised and unsupervised methods to construct feature hierarchies automatically by training systems composed of multiple stages of trainable modules.The recent history of OCR, speech recognition, and image analysis indicates that deep learning systems yield higher accuracy than systems that rely on hand-crafted features or "shallow" architectures whenever more training data and more computational resources become available. Deep learning systems, particularly convolutional nets, hold the performances record in a wide variety of benchmarks and competition, including object recognition in image, semantic image labeling (2D and 3D), acoustic modeling for speech recognition, drug design, handwriting recognition, pedestrian detection, road sign recognition, etc. The most recent speech recognition and image analysis systems deployed by Google, IBM, Microsoft, Baidu, NEC and others all use deep learning and many use convolutional nets.While the practical successes of deep learning are numerous, so are the theoretical questions that surround it. What can circuit complexity theory tell us about deep architectures with their multiple sequential steps of computation, compared to, say, kernel machines with simple kernels that have only two steps? What can learning theory tell us about unsupervised feature learning? What can theory tell us about the properties of deep architectures composed of layers that expand the dimension of their input (e.g. like sparse coding), followed by layers that reduce it (e.g. like pooling)? What can theory tell us about the properties of the non-convex objective functions that arise in deep learning? Why is it that the best-performing deep learning systems happen to be ridiculously over-parameterized with regularization so aggressive that it borders on genocide?
0:00 Learning Representations: A Challenge For Learning Theory
1:36 Learning Representations: a challenge for AI, ML, Neuroscience, Cognitive Science
2:44 Architecture of "Mainstream" Machine Learning Systems
3:47 This Basic Model has not evolved much since the 50's
4:06 The Mammalian Visual Cortex is Hierarchical
5:21 Let's be inspired by nature, but not too much
6:57 Trainable Feature Hierarchies: End-to-end learning
7:31 Do we really need deep architectures?
8:47 Why would deep architectures be more efficient?
9:41 Deep Learning: A Theoretician's Nightmare? - 1
11:34 Deep Learning: A Theoretician's Nightmare? - 2
12:54 Deep Learning: A Theoretician's Paradise?
13:56 Deep Learning and Feature Learning Today
15:04 In Many Fields, Feature Learning Has Caused a Revolution
16:25 Convolutional Networks
16:56 Early Hierarchical Feature Models for Vision
18:17 The Convolutional Net Model
18:20 Feature Transform - 1
19:03 Feature Transform - 2
19:12 Convolutional Network (ConvNet)
19:15 Convolutional Network Architecture
19:17 Convolutional Network (vintage 1990)
for more slides check http://videolectures.net/colt2013_lecun_theory/
How Deep Learning Will Enable Self Driving CarsDeep learning is a branch of artificial intelligence that teaches machines to understand unstructured data, such as images, speech and video, using algorithms—step-by-step data-crunching recipes.
In this meet-up with NVIDIA's Mike Houston, you'll learn how NVIDIA DIGITS, a deep learning training system, and the NVIDIA DRIVE PX car computer can understand the subtle nuances of what is happening around a vehicle. It can discern an ambulance from a delivery truck, determine whether a parked car is vacant or the door is opening as a passenger emerges, and can detect occluded objects, such as a pedestrian partially blocked by a parked car.
Deep Learning for Decision Making and ControlA remarkable feature of human and animal intelligence is the ability to autonomously acquire new behaviors. This research is concerned with designing algorithms that aim to bring this ability to robots and simulated characters. Levine will describe a class of guided policy search algorithms that tackle this challenge by transforming the task of learning control policies into a supervised learning problem, with supervision provided by simple, efficient trajectory-centric methods.
Sergey Levine is a postdoctoral researcher working with Professor Pieter Abbeel at UC Berkeley
Large-Scale Deep Learning for Building Intelligent Computer SystemsOver the past few years, we have built large-scale computer systems for training neural networks and then applied these systems to a wide variety of problems that have traditionally been very difficult for computers. We have made significant improvements in the state-of-the-art in many of these areas and our software systems and algorithms have been used by dozens of different groups at Google to train state-of-the-art models for speech recognition, image recognition, various visual detection tasks, language modeling, language translation, and many other tasks. In this talk, Google Senior Fellow Jeff Dean highlights some of the distributed systems and algorithms that Google uses in order to train large models quickly. He also discusses ways Google has applied this work to a variety of problems in its products, usually in close collaboration with other teams.
The Future of Robotics and Artificial Intelligence (Andrew Ng, Stanford University, STAN 2011)(May 21, 2011) Andrew Ng (Stanford University) is building robots to improve the lives of millions. From autonomous helicopters to robotic perception, Ng's research in machine learning and artificial intelligence could result one day in a robot that can clean your house.
STAN: Society, Technology, Art and Nature, was Stanford University's prototype conferecne for TEDxStanford, and showcased some of the university's top faculty, students, alumni and performers in an intense four-hour event laced with surprising appearances and memorable experiences. STAN, modeled after TED, explored big questions about society, technology, art and nature in a format that invites feedback and engagement.
Stanford University:
http://www.stanford.edu/
STAN 2011:
http://stan2011.stanford.edu
Andrew Ng:
http://ai.stanford.edu/~ang/
Stanford University Channel on YouTube:
http://www.youtube.com/stanford